Under certain circumstances it can be appropriate to release cases receiving a particular types of interpretation without review. This is known as auto-validation.
Auto-validation may be appropriate when:
- You have reviewed a large number of cases giving a particular interpretation, and that interpretation is now always correct whenever it is given, or
- The rules giving a certain type of interpretation are so general and simple that only minimal review is needed, or
- The project is not being used to provide reports, but to automate processes in the laboratory such as reflexive testing or billing actions.
You have three ways of managing auto-validation, either by rules, by reports, or by report sections.
With rule-based auto-validation, you add, modify or remove auto-validation settings that are given by the project using the rule wizard, in exactly the same way as you would if you were adding, modifying or removing comments using rules. This is the most flexible approach. See Managing auto-validation using rules.
To manage auto-validation on a “per report” basis, you set a percentage auto-validation level to each unique report that is generated by the knowledge base. This is the most restrictive policy, but the safest. See Managing auto-validation using reports.
To manage auto-validation on a “per report section” basis, you set a percentage auto-validation level to each unique report section that is generated by the knowledge base. This is the less restrictive than the “per report” policy. See Managing auto-validation using report sections.
The choice between the “per report’ and “per report section” policy is done using the menu ‘Autovalidation | Policy…’. See Setting the Policy.
For any particular project, the choices of “per report” or “per report section” are mutually exclusive. However, auto-validation by rules will take precedence over any “per-report” or “per report section” based levels. To see how this works, suppose firstly that the policy is “per-report”.
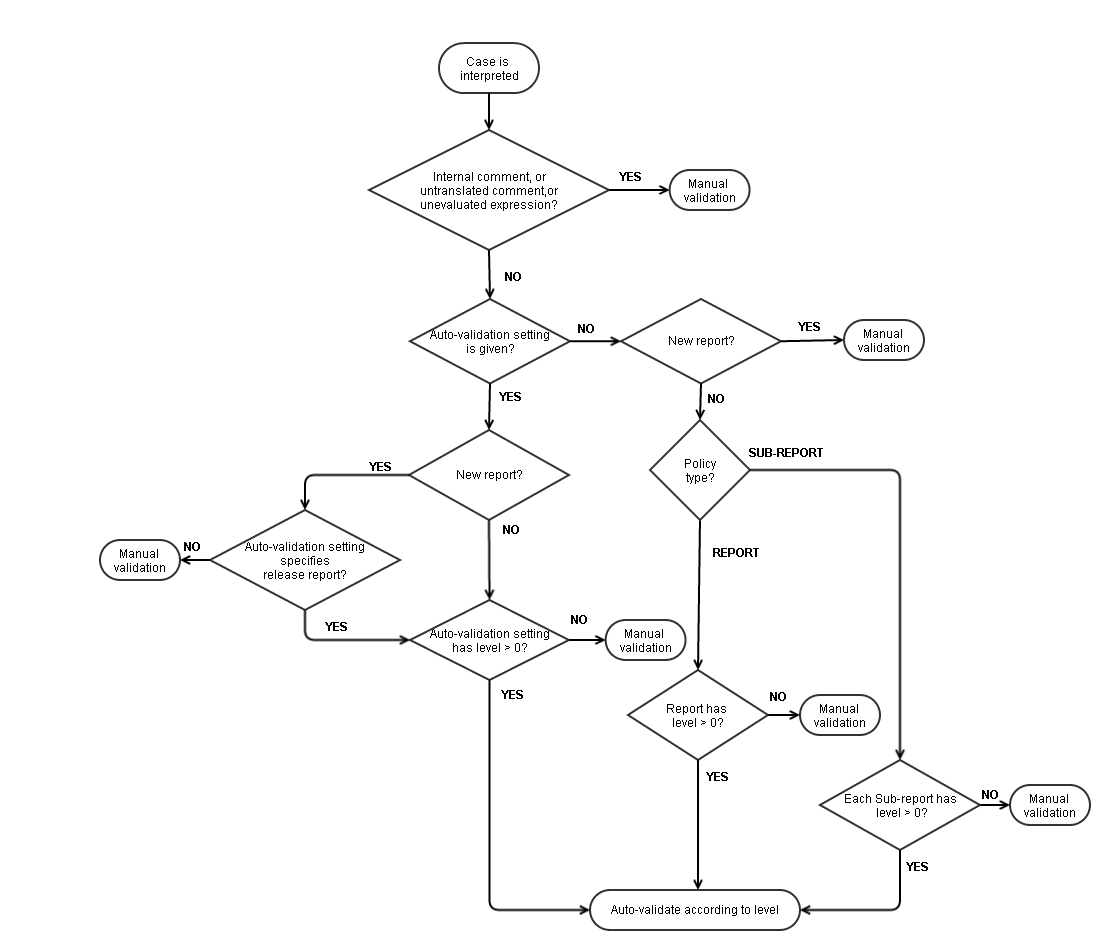
The decision whether to autovalidate a case is made as follows:
- If the report has not yet been enabled for autovalidation, the case is manually validated.
- If the report is enabled, and there is an autovalidation setting given for the case, i.e. based on rules, then the case is autovalidated with a probability determined by the level of that autovalidation setting (if there is more than one setting, the setting with the lowest level is used).
- If there is no autovalidation setting given for the case, then the case is autovalidated with a probability determined by the level of its report, (which may of course be zero).
Now suppose that the policy is “per report section”. The decision whether to autovalidate a case is similar to the steps above:
- If any report section in the case’s report has not yet been enabled for autovalidation, the case is manually validated.
- If all report sections are enabled, and there is an autovalidation setting given for the case, i.e. based on rules, then that setting is used to determine whether or not to auto-validate the case.
- If there is no autovalidation setting given for the case, then the lowest level of any report section given for the case is used to determine whether or not to auto-validate the case.
This algorithm is shown in the diagram below:
Note: In normal situations, it is advisable not set any autovalidation level above about 95%. This is so that you will still be able to review in validation at least some cases that giving that type of interpretation.