A data extraction spreadsheet can be generated by exporting cases from a Validator or Auditor queue, or from a Knowledge Builder case list.
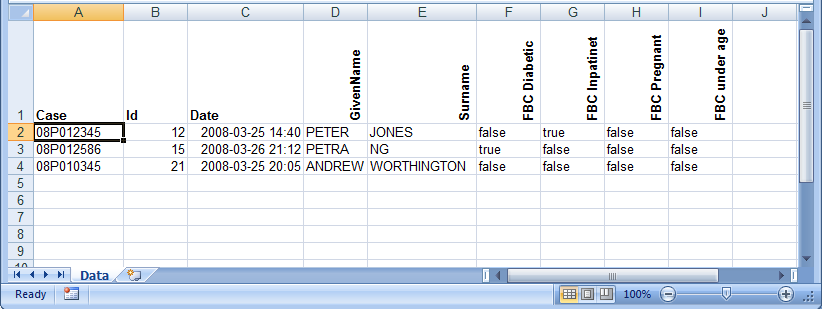
The first three columns are included by default in every spreadsheet:
- Case – the name of the RippleDown case for the patient, as used in Knowledge Builder case lists.
- Id – unique identifier for the case in the queue.
- Date – the date and time of the episode values shown in subsequent columns. If there is more than one episode for a case, there will be several rows with the same Case and Id, but different Dates.
Additional columns correspond to the attributes and features you specified in the data extraction definition dialog. The attributes appear first, sorted alphabetically. Any features and derived features are then shown, also in alphabetical order.